
By Raj Bhatti, SVP Client Solutions
Twenty-five years ago was the first time I heard a senior business leader say, “Our business is running off spreadsheets and this has to stop.” I had just started my career as a programmer at Lehman Brothers. Lehman does not exist today. But multibillion-dollar global businesses running off spreadsheets still exist.
I have been lucky enough to have held multiple C-level roles in technology, been a part of two very successful IPOs, and led multiple teams developing software that supported trillions of dollars in notional trading and risk. I have had a front row seat in the journey from DOS-based Paradox databases to SQL relational databases, to client-server, to world-wide-web, OLTP and OLAP, business intelligence to data warehouses, ODS to data marts to data lakes to data fabric, etc.
After all this, I can confidently say where I have seen the most data project failure: data and analytics projects attempting to move business critical operations and insights from spreadsheets to corporate systems.
If you’re still driving critical business decisions using spreadsheets after rolling out your data program, your project has failed.
Spreadsheet vs Database
I’m not anti-spreadsheet. Spreadsheets are likely the most powerful tool in the arsenal of the business world.
The issue is when your spreadsheet is your database.
The issue is when the only feasible way to support business decisions is STILL to maintain and use the data directly in legacy systems with countless manual hours being spent to collect, normalize, and analyze the data in spreadsheets.
Data Project Failure: The Usual Suspects
Project failure does not always mean a dramatic crash and burn. It means that the data program has not produced the outputs that were defined as the success criteria.
Data project failure can be caused because of the same reasons that cause any kind of project to fail:
Data Project Failure: Some Radical Observations from the Trenches
So far, I have covered things you likely already knew. Now I would like to list some startling reasons for failure I have come across again and again that you likely did not expect:
Over-engineering (“a camel is a horse designed by a committee”): Getting buy-in from all stakeholders results in the engineering goals being more focused on how to keep multiple balls in the air as opposed to designing the data architecture that most efficiently takes you from point A to point B. And everyone is a stakeholder in a data project.
Wrong tech priorities: The engineers’ desire to work on the latest and coolest technology plays a surprisingly oversized role in selecting technology. For many engineers, gaining technical expertise in a marketable skill for their resume carries more weight than determining the most optimal way of solving the problem at hand.
Lack of focus on data management: Although data management is where firms need to spend the majority of their time, it is usually not given the importance it deserves. This is the biggest reason users don’t trust the efficacy of the data, and this results in lack of adoption – which is failure.
Not having the data you thought you had: Collecting the data can be challenging. Creating or purchasing may not be possible. The data may not be clean. There may not be a way to process the data in a timely and cost-effective way. Limited research on client confidentiality and data privacy law implications are mistakes many rookies make.
Poor team composition: Every data project has a unique set of talent requirements. Building the right team is like George Clooney building his team for the heist in “Ocean’s 11.” A cookie-cutter approach to team composition happens all too often, resulting in not having specific talent needed for the specific data problems that you need to solve for.
Organizations go to analytics without having their data ready. Much work needs to be done to collect, normalize, and aggregate data. First-timers often make the mistake of not realizing that the bulk of the heavy-lifting in your “cool” data science project is getting the data lined up.
Lack of appreciation for the power of spreadsheets: I have seen many IT professionals tell business users to give up their spreadsheets and start using clunky dashboards that only provide half the data needed for the business user to do their job.
The goal should never be to stop the business from being able to use their spreadsheets for what spreadsheets were built for.
The goal should be for the data storage and heavy business-logic computations to happen on a back-end data platform. The business user should have the option to use new dashboard visualizations and/or export data from the data platform into their spreadsheet.
Why This Time Will Truly Be Different
The work being done in data sciences coupled with the ability to store, aggregate, and compute gazillions of petabytes of data will result in “haves” and “have nots” in the business world. Machine learning and AI models will be used in every element of every workflow. And only the firms that have lined up their data will have the ability to stay competitive (think DVDs vs. streaming).
The “brute force” solution of just hiring more people for data-entry will not hide your data program failure any longer.
Working the weekend compiling data in spreadsheets will no longer be enough to win.
Your competitors will have insights and analytics being sent realtime to their iPhones, while you are working on updating that pivot table.
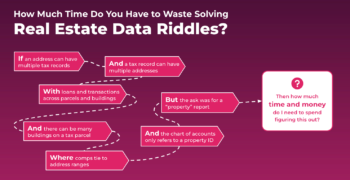
You’re barraged by real estate data sales pitches every day. Buzzwords like AI, Moneyball, or Bring-Your-Own-Data Visualization layers. But you rarely hear about implementations that drive ROI. That’s because most sales pitches are bullsh*t.

“The World As a Service: A peek into the future technology is creating.”
You won’t want to miss James Whittaker’s keynote at the inaugural Cherre Data Summit on May 19 in NYC: “The World As a Service: A peek into the future technology is creating.”

14 reasons your data project has failed (including reasons you’ve never heard before)
By Raj Bhatti, SVP Client Solutions
Twenty-five years ago was the first time I heard a senior business leader say,