
As I mentioned in the blog post on our Owner Unmasking Algorithm, a knowledge graph is an abstract way to organize and analyze knowledge, in which entities are represented as nodes and their relationships are represented as edges connecting nodes. A wealth of attributes can be associated with both nodes and edges.
In Cherre’s Knowledge Graph, entities are real estate properties, their addresses, as well as people and companies that operate in the real estate domain:
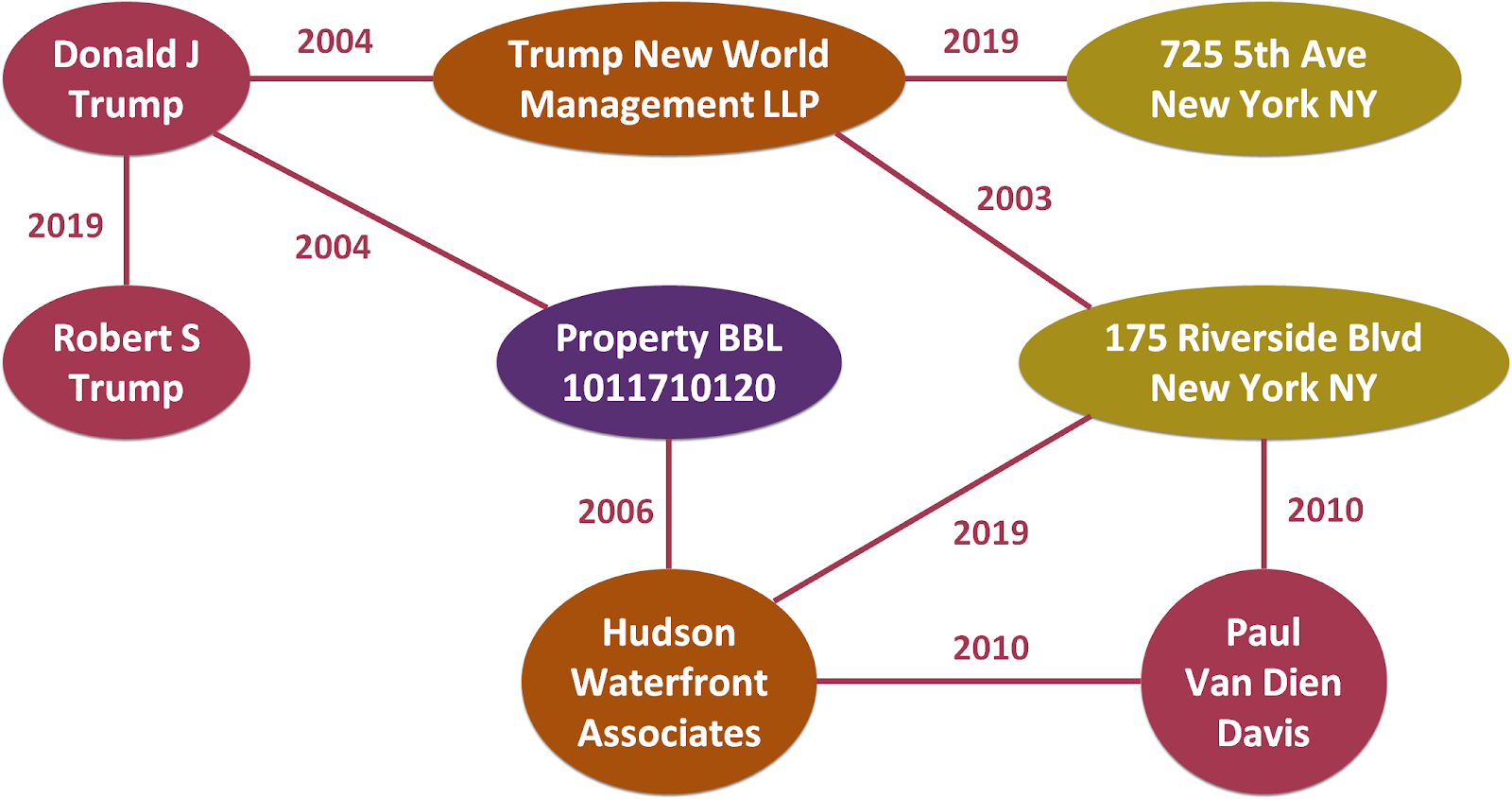
A knowledge graph is particularly useful for revealing hidden relationships between entities, by traversing the graph from one node to another over the edges. In the example above, a relationship between Donald Trump and Paul Davis can be made by starting at the Donald J Trump node, following an edge to Property 1011710120, following an edge to Hudson Waterfront Associates, and then following an edge to Paul Van Dien Davis. Revealing hidden relationships is very valuable in practical applications, such as Owner Unmasking.
The main challenge of Cherre’s Knowledge Graph is its large scale (e.g. billions of nodes and edges). Neither the structure nor the content of such a knowledge graph can be manually reviewed, which creates a battery of problems. For example, it’s not easy to assess the quality of the knowledge graph when you have billions of data points. And since a typical knowledge graph is constructed from (many) raw datasets, the quality of the knowledge graph should not be taken for granted.
Below is an example of a knowledge graph of a particularly low quality:

As you can see, the graph consists of small, disconnected subgraphs, which do not allow any traversing, and therefore makes the graph useless. Note that nodes on the left correspond to the same entity, represented in a slightly different format. The same is true for nodes on the right. Ideally, we should have merged all the nodes on the left into one node, and all the nodes on the right into one node as well. This merging procedure would improve the quality of the knowledge graph, both because duplications of the same entity would have been eliminated, and because the graph structure would become traversable.
Unfortunately, the real world situation is not as simple as in the example above, for which we could easily (and programmatically) detect that the graph is not traversable and decide that the graph is not useful. In the real world, the knowledge graph is substantially larger and is not easily breakable to connected components:
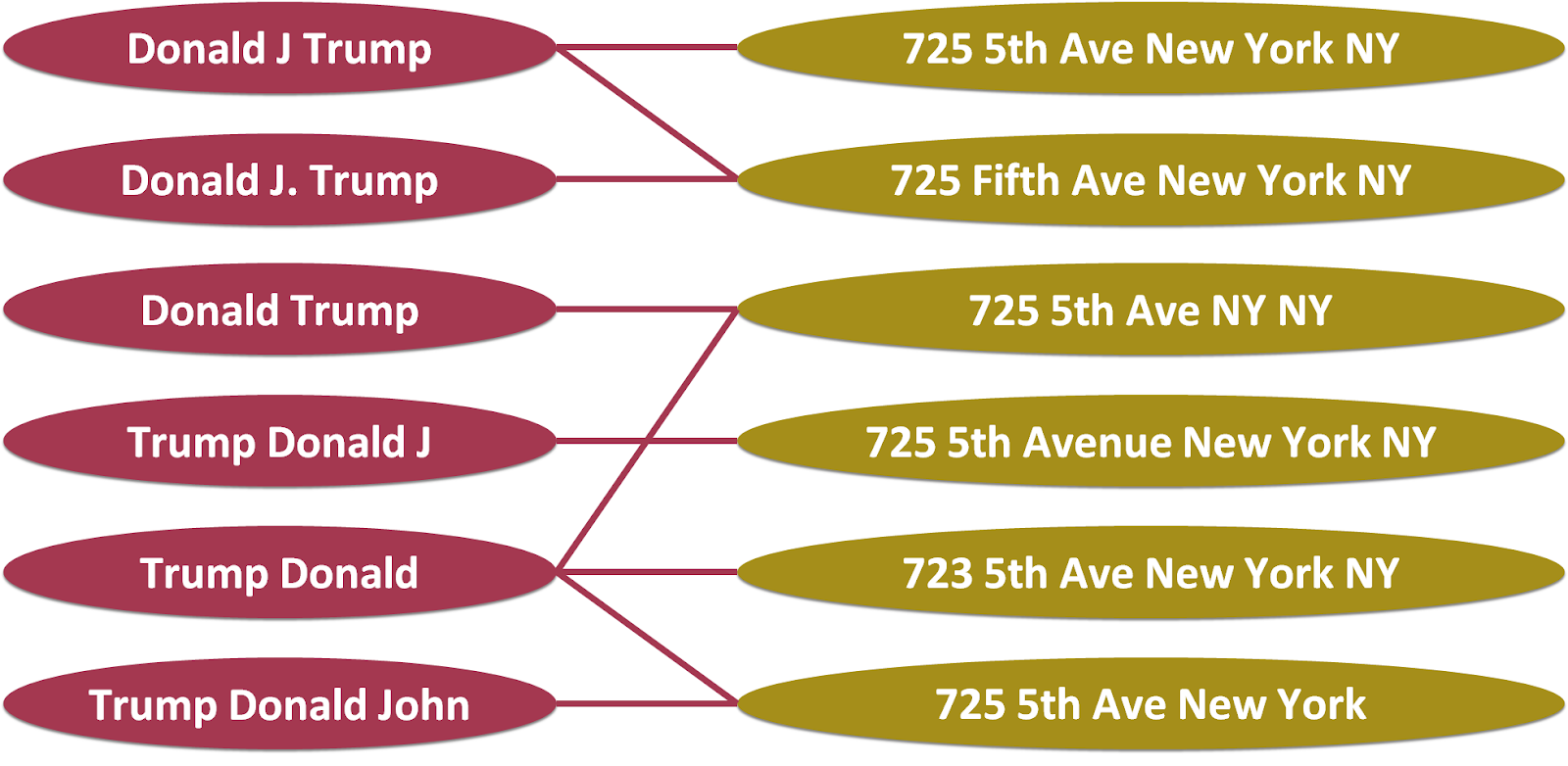
In the example above, it is no longer trivial to programmatically figure out that the quality of the graph is low, especially given that the graph is very large. Some simple heuristics can be used to merge nodes corresponding to the same entity. For instance, the top two nodes on the left differ only in a dot. A regular expression can be constructed to delete the dot, and then the two names would become the same. Let us assume that we have applied simple heuristics and compressed the graph above into the following version:

At this point, additional merging is not trivial because entities on the left differ substantially. For instance, a person named Trump, Donald J might have a full name of Trump, Donald James, which is different from Trump, Donald John. An address 725 5th Ave New York might be in a different state rather than in NY. However, in the context of other nodes in the graph, it would be safe to infer that Trump, Donald J and Trump, Donald John are very likely to be the same person, because they are very close to each other in the knowledge graph and their names are very similar to each other.
We define a semantic neighborhood of a node A in a graph as a set of its immediate neighbors (all nodes directly connected to A).
We propose a method for entity resolution in a knowledge graph (that is, merging together nodes that refer to the same entity) that is based on two observations:
We derive a method for assessing structural and linguistic similarity of nodes in a large-scale knowledge graph. Note that despite the existence of simple alternatives, our method has to be technologically advanced, because of the scale of a knowledge graph it has to deal with.
A technologically simple method would consist of two steps:
This method would need to execute over every pair of nodes, access their semantic neighborhoods, and try to overlap them. In a large-scale knowledge graph of, say, 10 million nodes, there would be 50 trillion node pairs, which would make the computation prohibitively slow (that is, many years to run – no exaggeration).
A different straightforward method would be:
This approach is not significantly faster than the previous one, because it still involves processing all pairs of nodes.
We notice that in the vast majority of cases, semantic neighborhoods of two randomly chosen nodes will not overlap, which means that not all pairs of nodes should be checked. If a semantic neighborhood of node A overlaps with a semantic neighborhood of node B, then there is a node C that belongs to both semantic neighborhoods of A and B. And here is the catch: A and B belong to the semantic neighborhood of C. That means that instead of checking all pairs of A and B in the graph (a quadratic algorithm over all nodes), we can check all pairs of nodes in the semantic neighborhood of C (a quadratic algorithm over all nodes within each semantic neighborhood). This dramatic improvement of computational complexity makes the computation feasible.
Moreover, we can integrate checking for semantic neighborhood overlaps with checking for node name similarity. Our algorithm is as follows:
The algorithm is applicable to graphs of any size, if semantic neighborhoods of its nodes are not too large. If they are, such semantic neighborhoods can simply be ignored, because they are not helpful for assessing structural similarities. For example, if a node in the knowledge graph corresponds to a very large apartment complex, and is connected to thousands of its tenants, chances for two tenants to know each other would be very low. If we ignore large semantic neighborhoods, our algorithm becomes scalable for any practical application.
So far so good, but we still have a problem: what should we do with Donald J. Trump and Donald J. Trump Jr.? The father and the son have very similar names and similar semantic neighborhoods in the knowledge graph. Using the solution above, we may mistakenly merge their nodes into one. I will address this problem in the next blog post.
Dr. Ron Bekkerman is the CTO of Cherre, overseeing Cherre’s emerging technologies. From 2013 to 2018, Ron was Assistant Professor and Director of the Big Data Science Lab at the University of Haifa, Israel.
You’re barraged by real estate data sales pitches every day. Buzzwords like AI, Moneyball, or Bring-Your-Own-Data Visualization layers. But you rarely hear about implementations that drive ROI. That’s because most sales pitches are bullsh*t.

“The World As a Service: A peek into the future technology is creating.”
You won’t want to miss James Whittaker’s keynote at the inaugural Cherre Data Summit on May 19 in NYC: “The World As a Service: A peek into the future technology is creating.”

14 reasons your data project has failed (including reasons you’ve never heard before)
By Raj Bhatti, SVP Client Solutions
Twenty-five years ago was the first time I heard a senior business leader say,