
Automating processes without losing your edge
In many companies, and especially in startups, growth is a critical objective. We strive to be doing more, doing better, and delivering more value day after day. However, organizations may experience an unfortunate conundrum where the very parts of their culture which enabled them to grow, are in fact stifled by growth itself.
For those organizations on the path to becoming elite DevOps performers, a culture of experimentation and learning is a key ingredient along the way. This can often be a precondition for the innovation and risk-taking needed to meet and exceed our goals. However, we also know that we can push technology growth further by automating processes and building self-service capabilities. If we’ve done this well, then we may find that many of our engineers no longer need to dive as deeply into the stack to do their daily work; a friendly UI or CLI takes care of most of it. This is the paradox that inspired this post. We learn the ins-and-outs when we need to for our work, but how can we retain our deep understanding once we’ve successfully abstracted the complexities away?
This is at the top of the list, and for good reason. A culture of blameless post-mortems is as important for organizational learning as it is for improving our systems over time. In an effective post-mortem, the investigators need to either leverage their existing understanding of the system, or dive beneath the surface to gain some insight. In either of these situations, post-mortem attendees can benefit from the knowledge sharing that occurs. These learning aspects can be further encouraged by creating a template for post-mortem documents with prompts for ‘Lessons Learned’. This may include how the incident response may have been handled differently, how a third-party service we use works differently from expected, and anything in between.
Injecting errors into production is a daunting and seemingly counterproductive prospect. However, if we’ve been practicing post-mortem culture, then we can see the learning opportunities that can come from errors of nearly any scale. Errors and outages are a part of our reality if we are consistently pushing the limits of what we can do. It can be tempting to rely on ‘hope’ and hide from this reality, but we are better off accepting it explicitly. When we inject errors into our systems, we get most of the benefits of unplanned outages and the subsequent post-mortems, but we also force people to think of a baseline level of failure recovery. There’s no way to address this without going deeper into the stack, and this makes that expectation explicit. Not only does this encourage learning and knowledge-sharing, it discourages the complacency of treating systems as black boxes.
Narrative-based knowledge sharing means focusing on the narrative of how a given system came to be designed a certain way. Usually this involves some storytelling of how we used to do something, the problems we faced, the things we tried, and how it all led to the way the system is built now. This can help to put things into perspective and understand the “intent” behind the design of systems, which helps equip people to make good design choices themselves when appropriate without having to check in with someone else who was there for the initial design. Describing the changes over time also requires peeling back some of the abstractions, because the underlying components were likely interacted with more directly in the past. This is something we can try to do while teaching our peers about systems we’re familiar with, but it can be systematized through the use of Architectural Decision Records. If we cultivate a practice of checking ADRs into source control along with the changes they describe, we’ve created a self-documenting repository for anyone who would like to learn more about a given system. A draft of an ADR can also be a key deliverable in design planning discussions, and subject to the same review process as our code changes.
Pair coding helps contribute to a learning culture in multiple ways. It can be an effective way to get people up-to-speed on a certain part of a codebase and helps keep knowledge de-siloed. Additionally, pair-coding ties in with Narrative-Based Knowledge Sharing, as described above, because in a pair-coding session some design decisions may be made together. Creating design documents in pairs can be beneficial for the same reason. This pays off because the decisions are likely to take into account multiple perspectives, and the participants will come away from the session with deeper knowledge to share with others in the company. Design choices made in isolation are unlikely to be well understood throughout the company.
Joel Lubinitsky is a Data Engineer at Cherre.
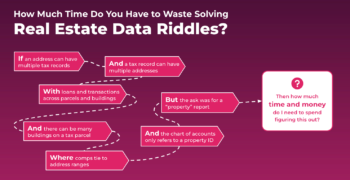
You’re barraged by real estate data sales pitches every day. Buzzwords like AI, Moneyball, or Bring-Your-Own-Data Visualization layers. But you rarely hear about implementations that drive ROI. That’s because most sales pitches are bullsh*t.

“The World As a Service: A peek into the future technology is creating.”
You won’t want to miss James Whittaker’s keynote at the inaugural Cherre Data Summit on May 19 in NYC: “The World As a Service: A peek into the future technology is creating.”

14 reasons your data project has failed (including reasons you’ve never heard before)
By Raj Bhatti, SVP Client Solutions
Twenty-five years ago was the first time I heard a senior business leader say,