
By L.D. Salmanson, Co-Founder and CEO of Cherre
In this four-part series, I take a birds-eye view of the world of real estate data and technology that we inherited. Only after we understand the historical context can we identify opportunities to use technology to fundamentally shift how we invest, manage, and transact this global asset class called real estate. Read previous article: Keeping a Low Profile During the Fintech (R)evolution
While real estate technology investment and adoption came abnormally slow for the largest asset class in the world over the last 20 years, it wasn’t non-existent.
For every intersection of geography, capital stack, investment, and asset class, there’s an abundance of applications and data solutions that add value to investors and operators – each evolved to meet a specific need – widely adopted by the industry.
Some of these solutions are incredibly powerful: ERP systems such as Yardi or MRI, modeling platforms such as Argus or Anaplan, lease CRMs such as VTS or Salesforce, and data vendors such as CoStar, REIS, RCA, or CompStak.

Going back in time is not an option. We inherited this world – a world that consists of an abundance of data and application solutions that have real value to the industry, but that are inherently incompatible with each other.
There’s no unified standard for any single object, let alone across the board. (Read about the challenges this causes with ESG data.) Even if a unified standard existed, we can’t go back in time and restructure the existing environment, of which there are many. Fragmentation and isolation is part of the world we inherit.
Competition and mutual suspicion amongst peers augment the problem. Data vendors have been extremely protective of their IP as a result of previous bad actors. Application vendors have opted for “walled garden” environments to increase switching costs, and bringing such vendors together to cooperate has been incredibly challenging historically. In fact, many are archenemies.
Real Estate Data Doesn’t Speak the Same Language
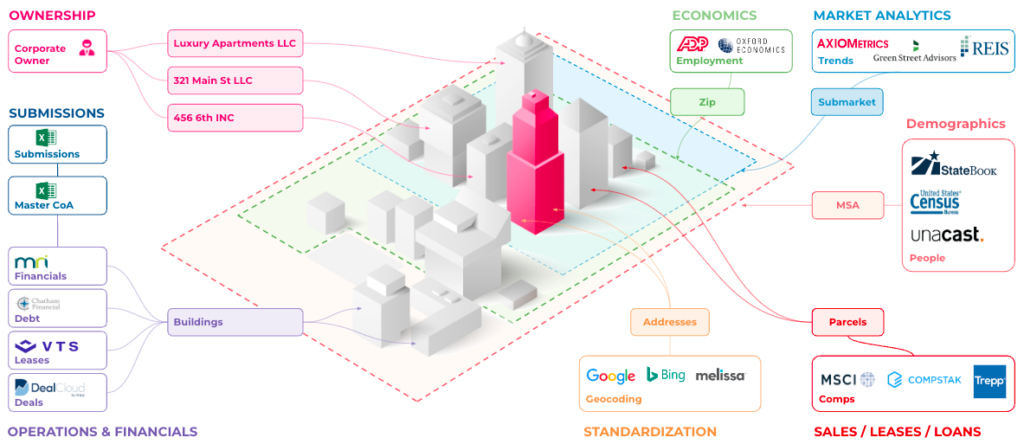
A seemingly simple question like “What is a property?” is an extremely difficult problem to solve. Are we referring to the tax lot, the physical structure, the commercial or residential unit, the address (or in reality, addresses), or some other identifier?
Untangling the web of real estate data has become an exercise in riddle solving.
The reason we’re asking the question creates further confusion. If I’m trying to get from point A to point B for navigation, understanding whether the address refers to the main entrance for a meeting or the back entrance for a delivery is critical. If I’m trying to map foot traffic to a building, I need to understand if the cell phone traffic went to the roof-top bar, the office space, the residential unit, the retail property at the base, or perhaps to the garage to pick up their car. The complexity is immense. A simple GIS solution is useless here. Parcels and buildings can overlap or be completely split, and neither account for three-dimensional environments. The world is complex, and we haven’t even begun to discuss the more challenging situations we face in real life.
Untangling the web of real estate data has become an exercise in riddle solving. Property data, valuations data, leasing data, and debt data might all tie together at the building level, but deal flow data is tied to a portfolio and transaction data is tied to the parcel. Market data and demographic data might be measured by Zip code, sub-market, or census tract. With ownership data, large corporate entities purchase properties under multiple, abstractly named LLCs that are deliberately obfuscated. The complexity today is incredible, and increasing by the minute with new data sets and applications required to power new use cases and business outcomes.
Up next: Moving the Industry Forward

We’re incredibly excited to announce that Cherre has joined RealPage.
Together, we’ll continue the same journey we started almost a decade ago at Cherre,

Combination connects property-level operations with institutional portfolio intelligence, giving owners and operators a governed, trusted foundation for better decisions and stronger performance
RICHARDSON,

For two decades, competitive advantage in institutional real estate ran on two rails: who you knew, and what your data stack could do.