
Welcome to Cherre’s Data Science Blog Series where we will highlight some of the cool things we’re working on, as well as provide overviews on key data science principles.
To know the real owner of a property is practically impossible in commercial real estate. This is because many properties are owned by LLC companies which act as “masking entities” – they shield the actual owner from exposure. While there are many benefits to owning properties through LLCs, there is one major drawback: when someone has an offer to make, they don’t know to whom to make it. This effectively kills real estate market liquidity and dramatically slows down the entire industry.
Cherre’s Owner Unmasking aims to uncover actual owners of properties by applying big data science methodologies. While it’s difficult to uncover an owner of one property of interest, doing that at scale for properties nationwide has long been considered science fiction. Cherre’s Real Estate Knowledge Graph helps us solve this problem at scale.
In computer science, a graph is a complex, visual object that consists of nodes and edges. Nodes (usually drawn as circles) correspond to real-world entities, while edges are lines drawn between the nodes – they correspond to real-world relationships between those entities. A wealth of attributes can be associated with each node, as well as with each edge, so that all together they may store a large amount of real-world knowledge – and that’s why such graphs are called knowledge graphs.
An example would be a node that corresponds to a single family residential property, and another node corresponding to a person. If an edge connects those two nodes, the edge depicts a relationship between the person and the property; for instance, the person might own the property. The attributes of the edge might shed light on the type of the relationship, such as in the example below.

Relationships that are usually quite straightforward in the residential space might be very complex in commercial real estate. A commercial property might be connected to hundreds of companies, people, and addresses, and those connections might be spread over many years. One thing is clear though: there is always a reason for why two entities are connected. If there was no relationship between two entities, there wouldn’t be an edge between their corresponding nodes in the knowledge graph.
This observation leads to a powerful method for discovering hidden relationships: if one node is connected to another, and the second node is connected to a third one, there would be a (probably non-trivial) relationship between the first and the third entities. If we traverse the knowledge graph around a specific node, we have a chance to discover how the corresponding entity is related to others. Those relationships might be important, and would be very difficult to understand without the help of a knowledge graph.
We use this method for Cherre’s Owner Unmasking: we start with a node that corresponds to a specific parcel, and we traverse Cherre’s Knowledge Graph around the parcel’s node, until we find a node that corresponds to a real estate investor. Then we ask a question: “What would be the reason for this investor’s node to be so close to this parcel’s node in the graph?” In most cases, the answer would be: “The nodes are so close because the investor is the true owner of this parcel.”
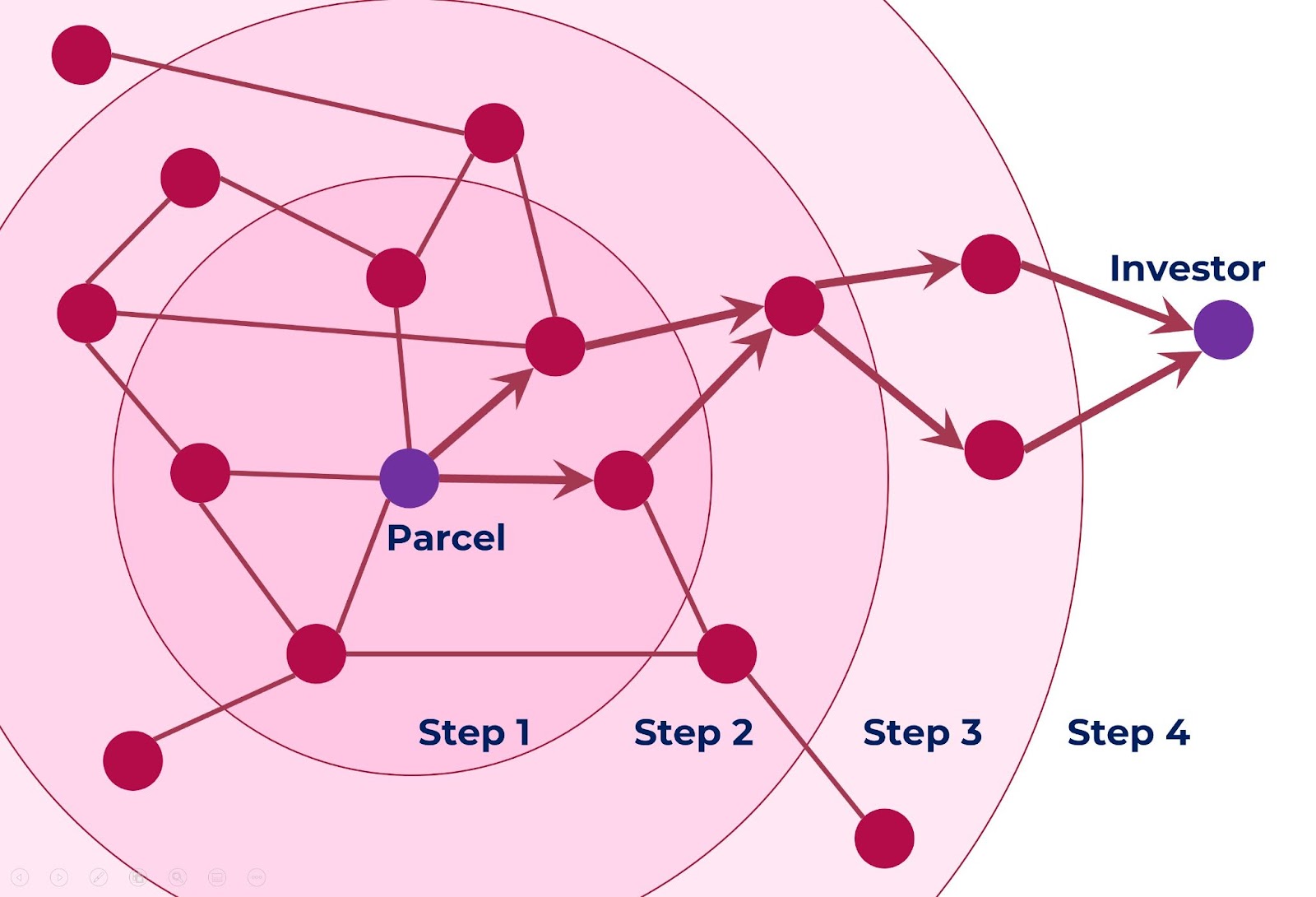
This approach has three main problems that we need to address. One is computational. Some of the parcel nodes in the knowledge graph are connected to hundreds of other nodes. If we start traversing the graph from such a well connected parcel, we will reach hundreds of nodes at step one, dozens of thousands of nodes at step two, millions at step three, etc. By the time we have finally found a node that corresponds to an investor, we would have processed millions of nodes. And since we need to unmask ownership of millions of parcels, we may end up processing millions of millions (that is, trillions) of nodes, which is too many even for the modern big data computational platforms.
Our solution to the computational problem is to start with nodes that are the neighbors of parcel nodes and of investor nodes in the knowledge graph – and traverse the graph towards parcel and investor nodes simultaneously. This way, we only have to make half as many steps, and process substantially fewer nodes, as depicted below:

Another problem to address is the strength of the connection between the parcel and the investor. If the path between them in the knowledge graph is long, the connection might be too weak, and in this case we might not be able to conclude that the investor is a probable owner of the parcel. On the other hand, if we can detect multiple paths between the parcel and the investor nodes (as in the example above), the strength of their connection increases.
The third problem is the recency of the connection. Since Cherre’s Knowledge Graph preserves historical information, some of the edges might correspond to connections that occurred in the past, and are no longer active. In our first example, the connection between Tiger Woods and his Florida house broke when he sold the house. While we still keep the corresponding edge in the graph, such an edge cannot be used to create paths that reveal the current ownership of properties. In the illustration below, historical connections are shown as dashed edges – they don’t participate in the paths between the parcel and the investor:

Cherre’s Knowledge Graph consists of about 0.5 billion nodes and about 1.5 billion edges. Being a full-scale model of the entire real estate ecosystem, it is a strong basis for a variety of analytics applications. We have demonstrated one of them – Cherre’s Owner Unmasking. We are working on a few others and will present them as soon as they are released.
Dr. Ron Bekkerman is the CTO of Cherre, overseeing Cherre’s emerging technologies. From 2013 to 2018, Ron was Assistant Professor and Director of the Big Data Science Lab at the University of Haifa, Israel.
You’re barraged by real estate data sales pitches every day. Buzzwords like AI, Moneyball, or Bring-Your-Own-Data Visualization layers. But you rarely hear about implementations that drive ROI. That’s because most sales pitches are bullsh*t.

“The World As a Service: A peek into the future technology is creating.”
You won’t want to miss James Whittaker’s keynote at the inaugural Cherre Data Summit on May 19 in NYC: “The World As a Service: A peek into the future technology is creating.”

14 reasons your data project has failed (including reasons you’ve never heard before)
By Raj Bhatti, SVP Client Solutions
Twenty-five years ago was the first time I heard a senior business leader say,